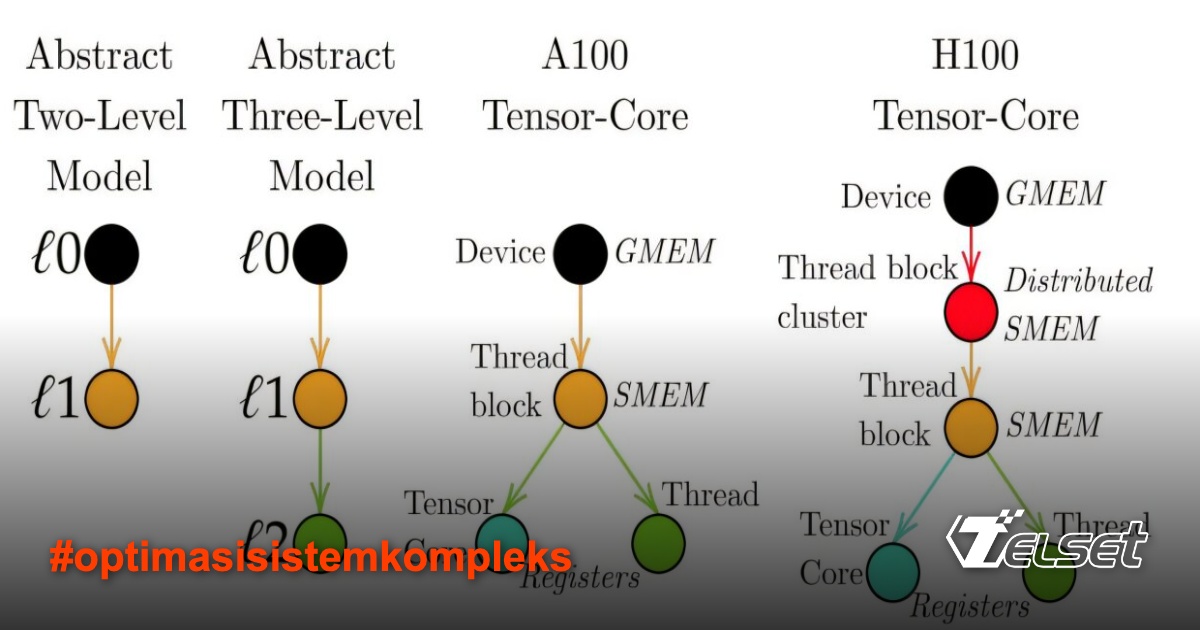
Telset.id – Bayangkan jika mengoptimalkan sistem rumit seperti jaringan transportasi kota atau komponen robot canggih bisa semudah menggambar diagram di atas serbet. Itulah yang ditawarkan oleh terobosan terbaru dari Massachusetts Institute of Technology (MIT). Para peneliti mengembangkan bahasa berbasis diagram yang menyederhanakan proses optimasi algoritma deep learning—hingga bisa direpresentasikan dalam coretan sederhana.
Penelitian ini dipimpin oleh Vincent Abbott, calon doktoral, dan Profesor Gioele Zardini dari MIT’s Laboratory for Information and Decision Systems (LIDS). Mereka memublikasikan temuan mereka dalam Transactions of Machine Learning Research, dengan judul provokatif: “FlashAttention on a Napkin”. Judul ini bukan hiperbola—metode mereka benar-benar memungkinkan pengoptimalan algoritma kompleks hanya dengan menggambar diagram hierarki.

Mengapa Ini Revolusioner?
Deep learning, fondasi dari model AI seperti ChatGPT dan Midjourney, bergantung pada matriks komputasi yang sangat rumit. Setiap perubahan dalam satu bagian sistem dapat memengaruhi bagian lain secara berantai. Biasanya, menemukan optimasi membutuhkan trial and error bertahun-tahun. Contohnya, FlashAttention—sebuah algoritma yang mempercepat komputasi “attention” dalam model bahasa besar—perlu waktu empat tahun untuk dikembangkan.
“Kami merancang bahasa baru untuk memahami sistem ini,” kata Zardini. Bahasa ini didasarkan pada category theory, cabang matematika yang mempelajari abstraksi dan komposisi sistem. Dengan pendekatan ini, hubungan antara algoritma dan perangkat keras (seperti GPU NVIDIA) dapat divisualisasikan secara jelas. “Ini seperti string diagram, tapi lebih kuat,” tambahnya.
Baca Juga:
Dampak pada Industri AI
Optimasi sumber daya adalah kunci dalam pengembangan AI. Model seperti DeepSeek membuktikan bahwa tim kecil bisa bersaing dengan raksasa seperti OpenAI jika fokus pada efisiensi. Namun, selama ini tidak ada metode sistematis untuk memahami hubungan antara algoritma dan konsumsi daya, memori, atau kinerja.
“Kami bisa menurunkan FlashAttention hanya dengan diagram di serbet—meski mungkin serbet yang agak besar,” canda Zardini. Pendekatan ini membuka pintu bagi otomatisasi optimasi algoritma. Di masa depan, peneliti cukup mengunggah kode, dan sistem akan mengembalikan versi yang sudah dioptimalkan.
Jeremy Howard, CEO Answers.ai, menyebut penelitian ini “langkah sangat signifikan.” Sementara Petar Velickovic dari Google DeepMind memuji kejelasan dan aksesibilitasnya. “Ini penelitian teoretis yang indah, tapi mudah dipahami,” katanya.
Dengan minat besar dari pengembang, metode ini berpotensi mengubah cara kita mendesain algoritma AI. Apakah ini awal dari era baru optimasi berbasis visual? MIT sudah membuktikan: terkadang, solusi terbaik memang dimulai dari coretan sederhana.



