
Telset.id – Hanya setahun setelah meluncurkan model yang mengguncang pasar global, DeepSeek dari China kembali dengan dua rilis terbaru yang penuh ambisi. Kabarnya, model open-source teranyar mereka, DeepSeek V3.2 dan V3.2-Speciale, mampu menyaingi atau bahkan mengungguli sistem AI paling canggih saat ini, termasuk GPT-5 dari OpenAI dan Gemini 3 Pro dari Google. Apakah ini awal dari pergeseran kekuatan di peta kecerdasan buatan dunia?
Jika Anda mengira perlombaan AI hanya tentang siapa yang memiliki kluster chip paling besar dan mahal, pikirkan lagi. DeepSeek justru mendobrak narasi itu dengan strategi yang berfokus pada efisiensi. Sementara laboratorium-laboratorium di Amerika Serikat mengandalkan kekuatan komputasi raksasa, DeepSeek berargumen bahwa pendekatan pelatihan yang lebih halus dan cerdas dapat menghasilkan kecerdasan serupa dengan perangkat keras yang lebih terjangkau. Ini bukan sekadar klaim kosong. Perusahaan tersebut menyatakan bahwa bahkan model standar V3.2 sudah dilengkapi dengan kemampuan penalaran penggunaan alat (tool-use reasoning) secara native. Artinya, pengguna mendapatkan kemampuan berpikir terstruktur tanpa harus beralih ke mode penalaran khusus—sebuah kemewahan yang seringkali hanya ada pada model premium.
Namun, sorotan utama tentu saja tertuju pada V3.2-Speciale. DeepSeek dengan percaya diri mengklaim bahwa versi ini telah melampaui kinerja GPT-5 dalam benchmark internal dan setara dengan Gemini 3 Pro dalam tugas-tugas yang berat akan penalaran. Sebagai bukti, mereka mengarahkan perhatian publik pada performa kuat dalam Olimpiade Matematika Internasional 2025 dan Olimpiade Informatika Internasional. Yang menarik, entri final mereka dipublikasikan untuk diperiksa oleh siapa saja—sebuah langkah transparansi yang jarang dilakukan raksasa AI lainnya. Lantas, dari mana lompatan performa yang begitu signifikan ini berasal?

DeepSeek mengaitkan keberhasilannya pada dua inovasi utama. Pertama, mekanisme perhatian renggang (sparse-attention) kustom yang dirancang khusus untuk efisiensi konteks panjang. Kedua, dan mungkin yang lebih krusial, adalah pipeline pembelajaran penguatan (reinforcement learning) yang diperluas, yang dilatih pada lebih dari 85.000 tugas kompleks dan multi-tahap. Semua tugas ini diciptakan melalui sistem “sintesis tugas agenik” (agentic task synthesis) internal mereka sendiri. Bayangkan sebuah pabrik yang tidak hanya memproduksi AI, tetapi juga secara otomatis menghasilkan kurikulum pelatihan yang semakin sulit untuk mendidik AI-nya sendiri. Itulah esensi dari lompatan ini. Pendekatan ini mengingatkan kita pada evolusi model open-source sebelumnya seperti DeepSeek V3-0324, yang juga fokus pada efisiensi, namun kini ditingkatkan skalanya dengan ambisi yang jauh lebih besar.
Strategi ini bukan tanpa risiko. Bergantung pada sistem sintesis internal membuka pertanyaan tentang bias dan keamanan data yang digunakan. Seperti yang pernah terjadi pada kasus kode AI AS yang diduga menggunakan model China, isu transparansi dan asal-usul data pelatihan selalu menjadi ranah yang sensitif. Namun, dengan mempublikasikan hasil benchmark dan entri olimpiade, DeepSeek seolah ingin mengatakan, “Nilailah sendiri hasilnya.”
Baca Juga:
Akses Terbatas dan Misi yang Jelas
Bagi Anda yang penasaran dan ingin segera mencoba, DeepSeek V3.2 sudah dapat diakses melalui situs web, aplikasi seluler, dan API perusahaan. Ini adalah kabar baik bagi developer dan peneliti yang ingin bereksperimen dengan model canggih tanpa biaya langganan yang menguras kantong. Namun, V3.2-Speciale yang lebih eksperimental hanya tersedia melalui endpoint API sementara yang rencananya akan dihapus setelah 15 Desember 2025. Saat ini, ia berjalan sebagai mesin yang hanya khusus untuk penalaran, tanpa kemampuan pemanggilan alat. Batas waktu ini menciptakan rasa urgensi sekaligus menimbulkan pertanyaan: Apakah ini bagian dari pengujian terbatas, atau strategi pemasaran yang cerdik untuk membangun eksklusivitas?
Terlepas dari itu, pesan yang ingin disampaikan DeepSeek semakin jelas. Mereka bertekad membuktikan bahwa AI tingkat atas tidak harus datang dengan harga yang juga tingkat atas. Dalam industri di mana biaya pelatihan model bisa mencapai ratusan juta dolar, filosofi efisiensi DeepSeek ibarat angin segar—atau mungkin badai yang mengancam status quo. Klaim yang berani ini menempatkan tekanan baru pada pemain industri lain, memaksa mereka untuk memikirkan ulang apa yang mungkin dan apa yang diperlukan untuk tetap kompetitif. Ketika sebuah perusahaan dari China bisa menghasilkan model yang diklaim setara dengan GPT-5 dengan sumber daya yang lebih optimal, apakah era dominasi mutlak lab-lab AS mulai menemui tantangan serius?
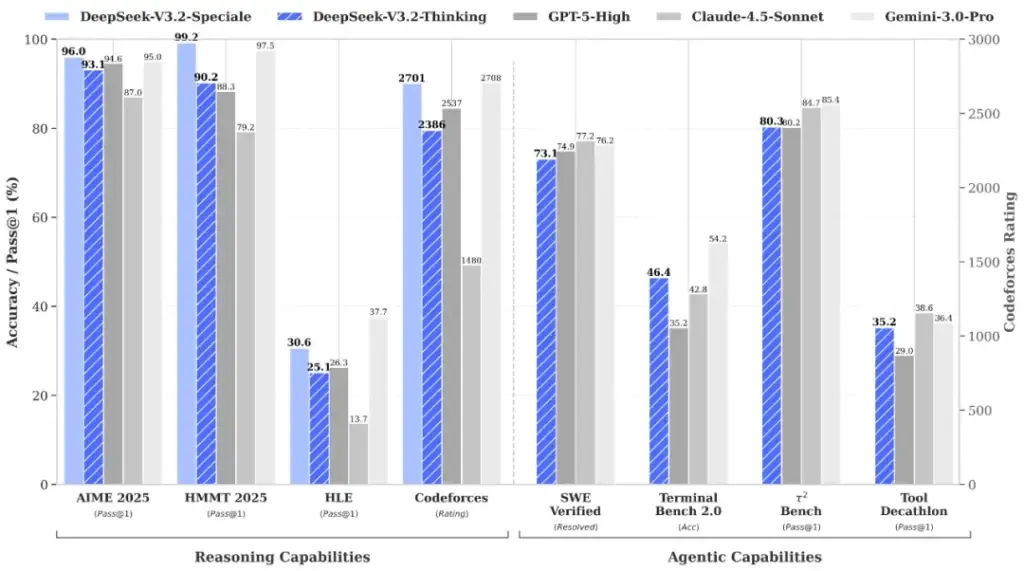
Menunggu Verifikasi Independen dan Masa Depan yang Terbuka
Patut diingat, klaim “mengalahkan GPT-5” tentu masih perlu diverifikasi secara independen oleh komunitas riset global. Benchmark internal, meski menjanjikan, bukanlah penilaian final. Komunitas AI kini akan menguji sendiri kemampuan DeepSeek V3.2 dalam berbagai tugas dunia nyata. Namun, satu hal yang tidak bisa dipungkiri: kehadiran DeepSeek telah menyuntikkan dinamika baru yang sehat dalam perlombaan AI. Mereka menawarkan alternatif, bukan sekadar peniru.
Filosofi open-source yang mereka pegang, meski dengan beberapa batasan pada model “Speciale”, membuka peluang bagi inovasi yang lebih terdistribusi. Ini kontras dengan beberapa kontroversi yang melanda pemain lain, seperti penyalahgunaan model generatif untuk konten berbahaya yang terjadi pada Sora 2 OpenAI yang disalahgunakan untuk stalking dan deepfake. Persaingan ketat di bidang AI tidak hanya soal kemampuan teknis, tetapi juga tentang tata kelola, etika, dan aksesibilitas.
Jadi, apakah DeepSeek V3.2 benar-benar menjadi “pembunuh raksasa” seperti yang diklaim? Waktu dan serangkaian pengujian rigor yang akan menjawabnya. Tetapi, dengan merilis model yang powerful dan relatif mudah diakses, DeepSeek setidaknya telah berhasil melakukan satu hal: membuat semua orang—dari penggemar teknologi, developer, hingga eksekutif di OpenAI dan Google—duduk dan memperhatikan. Mereka telah membuktikan bahwa dalam perlombaan AI, terkadang kecerdasan dalam mendesain algoritma bisa lebih berharga daripada sekadar menumpuk transistor. Dan itu adalah pelajaran yang berharga bagi seluruh industri.